From secure AI agent execution and declarative infrastructure to large-scale production migrations and bare metal automation, these talks highlight why OpenStack remains the open infrastructure platform powering the next generation of cloud and AI workloads.
Declarative Infrastructure for Modern OpenStack Clouds
As Kubernetes and OpenStack become increasingly complementary, operators are finding new ways to manage physical infrastructure with cloud native principles. Declarative Underlays: Scaling Purpose-Built Infrastructure (Clusters) for OpenStack with Cluster API explores how Cluster API can be used to provision and manage specialized GPU, networking, and storage clusters while dynamically rebalancing resources across large OpenStack environments.
AI is Changing How OpenStack is Built
Spec-Driven Evolution: How AI Agents are Rewriting the OpenStack/K8s Playbook demonstrates how AI coding agents can accelerate upstream development by transforming technical specifications into architectural proposals, production-ready code, and automated test suites for OpenStack Tacker—all while maintaining collaborative open source workflows.
Securing AI Workloads on OpenStack
As AI agents move into production, securely executing AI-generated code has become a critical challenge. Secure AI Agent Sandboxing with OpenStack Zun and Kata Containers showcases an OpenStack-native approach that combines Zun, Kata Containers, Glance, and Neutron to provide hardware-level isolation for untrusted AI workloads without sacrificing scalability or flexibility.
Optimizing Performance and Operations
Strong workload isolation is only valuable if you can observe what’s happening beneath the surface. Uncovering Hidden Bottlenecks in Kata Containers on OpenStack with Prometheus shares practical techniques for identifying CPU, memory, and I/O bottlenecks that traditional monitoring often misses, helping operators improve reliability in production environments.
Modernizing Infrastructure from Bare Metal to the Cloud
The final OpenStack session, Redesigning OpenStack i18n for the AI Era: Weblate & Zero-GPU AI, looks beyond infrastructure to the community itself. The talk highlights the OpenStack internationalization team’s migration to Weblate, AI-assisted translation running entirely on CPUs, and how these efforts are helping make OpenStack more accessible to contributors around the world.
Join the OpenStack Community in Shanghai
Together, these sessions reflect the momentum behind OpenStack as it continues to power private clouds, AI infrastructure, edge deployments, and cloud native platforms around the world.
If you’re attending KubeCon + CloudNativeCon + OpenInfra Summit + PyTorch Conference China, be sure to add these sessions to your schedule and stop by the OpenInfra Foundation booth to meet OpenStack users, contributors, and maintainers from across the global community.
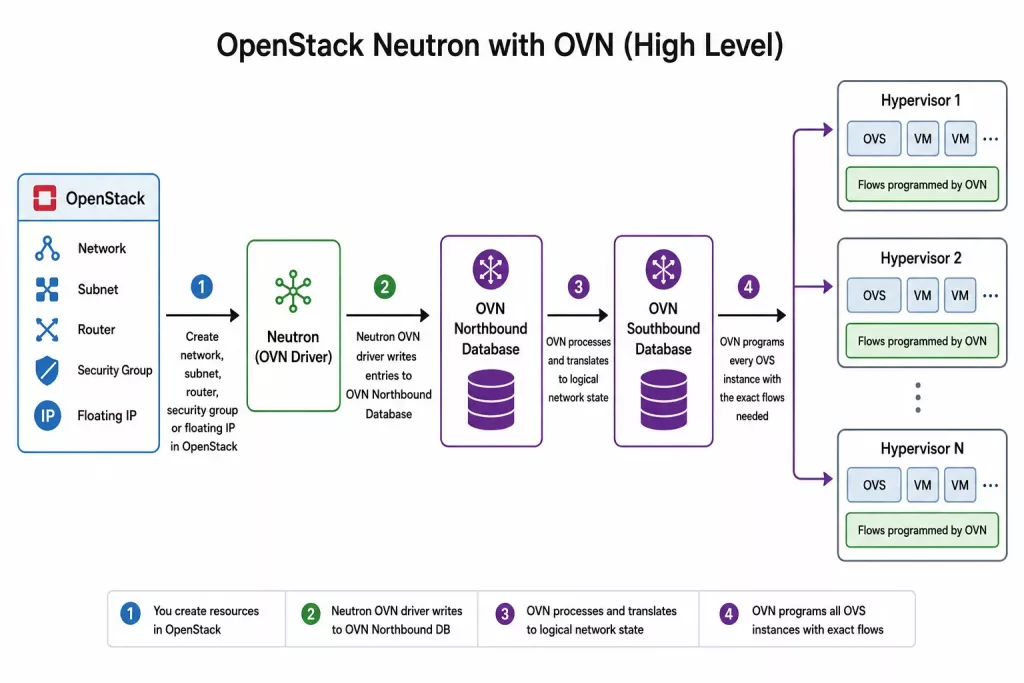
Open vSwitch gave us a programmable dataplane. Open Virtual Network added a control plane. Together they power Neutron in most OpenStack clouds. This tutorial explains the architecture, compares OVS vs. OVN, and shows how to trace a packet from instance to instance in OpenStack.
You’ve deployed two instances on different compute nodes. Same tenant. Same network. They can’t ping each other. Security groups allow ICMP. The physical network is up. Sound familiar? In OpenStack Neutron with OVN, most cross-host packet losses are not bugs – they are logical flow denials waiting to be read.
When your OpenStack instances can ping each other on the same compute node but go silent across hypervisors, you’re dealing with a networking failure that spans two layers: the dataplane and the control plane. Understanding how OVS and OVN operate across those layers turns a frustrating mystery into a solvable problem — because that’s where most OpenStack networking issues actually hide.
What is SDN? (Software-Defined Networking)
Before we dive into OVS and OVN, it helps to understand why these technologies exist in the first place.
Traditional networking works like this: each switch and router has its own control plane deciding where packets go and data plane forwarding packets. To change how traffic flows, you reconfigure each device individually – often by using protocols like NETCONF or RESTCONF. This approach works until you need to scale. In a cloud environment with hundreds of hypervisors and thousands of VMs, manual per-device configuration becomes impossible.
Software-Defined Networking (SDN) changes the game by separating the control plane from the data plane. A central SDN controller decides where traffic should go, and the underlying switches and routers simply follow those instructions. This separation brings three major benefits to cloud environments:
Benefit
Why it matters in cloud environments
Centralized control
You manage network policy centrally, not per-switch
Programmability
Networks adapt dynamically as VMs are created, migrated, or deleted
Automation
No manual switch configuration
OVS and OVN are SDN technologies. OVS provides the high-performance data plane on each hypervisor. OVN provides the distributed control plane that tells OVS what to do. Together, they implement SDN for OpenStack Neutron.
What is Open vSwitch?
Open vSwitch (OVS) is an open source virtual switch that speaks OpenFlow, supports tunnel encapsulation (VXLAN, GRE, Geneve), and integrates with KVM, Xen, and other virtualization platforms. Unlike basic Linux bridges, OVS was built for large data center environments: it handles high throughput via a kernel module, gives you visibility with sFlow/NetFlow, and lets you apply QoS per flow.
OVS became the default switch for OpenStack Neutron back in 2012. But it had a limitation: it exposed low-level OpenFlow rules, not logical network abstractions like “virtual router” or “security group”. Managing OVS directly at scale meant writing complex flows via CLI as Neutron OVS Agent did back in the days. And that was the point where OVN came in.
OVN – The Control Plane OVS was Missing
Open Virtual Network (OVN) started as part of the OVS project in 2013 and reached maturity by 2016. OVN does not replace OVS. It sits on top of it, providing a logical networking model – virtual switches, routers, ports and ACLs that are translated automatically into OpenFlow rules inside OVS.
Think of it this way:
OVS = the worker who moves packets
OVN = the manager who decides where packets should go and remembers the network topology
Today, OVN is the default Neutron driver in most OpenStack distributions. When you create a network, subnet, router, or security group in OpenStack, Neutron calls the OVN driver. That driver writes entries into OVN’s Southbound Database. OVN then programs every OVS instance on every hypervisor with the required flows.
OVS vs. OVN – Comparison Table
Aspect
OVS alone
OVS + OVN
Control plane
None (you configure flows manually or via OpenFlow controller)
Built-in distributed control plane
Logical abstractions
No – you work with ports, flows, tunnels
Yes – logical switches, routers, ports, ACLs
OpenStack integration
Mapping from Neutron to OVS flows
Native driver (Neutron ML2/OVN) with automation
Scalability
Flow table explosion in large environments
Southbound DB aggregates topology allowing larger scale
Typical use case
Standalone SDN dataplane or simple labs, old releases of OpenStack, Proxmox
OpenStack from Ussuri release, Kubernetes (OVN-K8s)
Learning curve
Low for basic switching, steep for OpenFlow
Moderate – you think in logical networks, not flows
Bottom line: OVS standalone can be used for small labs or test setups. OVN is what makes automated networking work at a cloud scale.
Why ML2/OVN Became the Standard
For many years, ML2/OVS was the most widely used OpenStack Neutron backend. In this architecture, Open vSwitch (OVS) handled packet forwarding, while Neutron agents provided services such as routing and DHCP. This approach introduced additional agents to manage, showed scaling limitations and had the infamous full-sync issue which could bring Neutron database or RabbitMQ down when too many neutron-openvswitch-agents were restarted at once.
OVN was designed to simplify OpenStack networking by integrating networking functions into a distributed SDN architecture. Instead of relying on multiple Neutron agents, OVN provides native support for routing, DHCP, and network policy management through a centralized control plane and distributed data plane.
The main advantages of ML2/OVN include:
Fewer agents to manage
Better scalability for large cloud environments
Native distributed routing and DHCP services
Simpler operations and troubleshooting
As OVN matured, it became the primary focus of networking development within the OpenStack community. By 2023.1 (Antelope) release ML2/OVN became the default solution in most OpenStack deployment tools and vendor solutions reflecting the broader shift toward OVN as the preferred backend.
For all new OpenStack deployments, ML2/OVN is the recommended choice and is considered the standard approach for modern OpenStack networking. Older deployments still using ML2/OVS are encouraged to migrate to ML2/OVN.
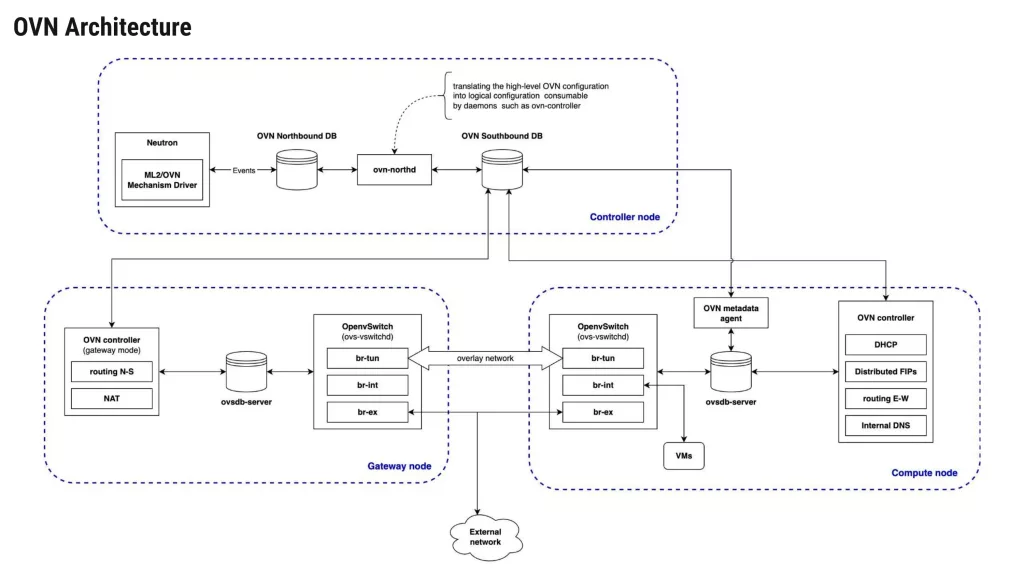
OVN Architecture Overview
At a high level, OVN separates responsibilities into two distinct layers:
Control plane
Data plane
The control plane is responsible for defining how the virtual network topology should look like. And the data plane is responsible for actually forwarding packets according to the topology and instructions.
This separation allows OVN to maintain a consistent network model while distributing packet processing across the infrastructure.
Control Plane Components
At the top of the architecture sits OpenStack Neutron.
When users create Networks, Routers, Subnets, Security groups, or Floating IPs through OpenStack APIs, Neutron passes this information to the ML2/OVN mechanism driver.
The mechanism driver converts OpenStack networking objects into OVN logical entities and stores them inside the OVN Northbound Database (NBDB).
The Northbound Database represents the desired state of the network. It answers the question: “What should the virtual network look like?”
When OpenStack users create networking resources, the ML2/OVN driver converts those resources into OVN logical objects and stores them in the Northbound Database.
Examples include:
Logical switches
Logical routers
ACLs
NAT policies
Load balancers
Logical ports
The ovn-northd is the central control daemon of OVN. It acts as a translator between the Northbound and Southbound databases.
Its responsibility is to:
Read logical network definitions from the Northbound Database.
Convert them into implementation details.
Populate the Southbound Database.
Whenever a network change occurs, ovn-northd recalculates the required network behavior and distributes updated information throughout the environment.
Data Plane Components
The Southbound Database (SBDB) acts as the communication layer between OVN’s control plane and the individual hosts running workloads. It answers the question: “How should each node implement the desired network state?”
It contains implementation-specific information such as:
Chassis registrations
Tunnel endpoints
Datapath bindings
Port bindings
Flow information
Each compute node and gateway node runs:
Open vSwitch
OVSDB
ovn-controller
The ovn-controller process continuously monitors the Southbound Database and retrieves configuration relevant to its local chassis (compute or gateway node).
It then programs Open vSwitch accordingly by creating:
Tunnel configurations
Datapath entries
Logical flows
OpenFlow rules
This enables each node to enforce networking behavior independently while remaining synchronized with the cluster.
Overview of Components:Northbound Database (NB DB) Stores the logical network configuration as intended by the administrator or OpenStack. Example entries: logical switches, routers, ports, ACL rules. Neutron writes directly to the NB DB via the OVN driver.Southbound Database (SB DB) Stores the actual, low-level state calculated from the NB DB. Each chassis (OVS on hypervisor) reports its local OVS port bindings here. The SB DB also holds logical flow tables – a mid-level representation between Neutron’s intent and OVS’s OpenFlow rules.ovn‑controller Runs on every compute node. It watches the SB DB, translates logical flows into OpenFlow flows, and pushes them into the local br-int integration bridge. It also reports back local port status and tunnel endpoint IPs.ovn‑northd Runs on a centralized controller node. Its job is to translate the Neutron-configured NB DB into the more detailed, distributed-ready SB DB. It runs continuously, watching for changes and updating the SB DB accordingly.Tunnel overlay OVN uses tunnels (Geneve or VXLAN) to carry traffic between compute nodes. Each OVN chassis has a tunnel endpoint IP. When a packet leaves a VM, OVN encapsulates it and sends it to the destination chassis, where decapsulation happens before delivery. Tunnel overlays work over both L2 and L3 networks allowing greater cloud scalability.
Understanding the OVN Workflow
The complete workflow is essentially a seven-step process:
User creates a network resource in OpenStack.
Neutron writes the logical configuration to the Northbound Database.
ovn-northd converts logical intent into implementation details.
That information is written into the Southbound Database.
Local ovn-controller processes receive updates.
Open vSwitch is (re-)programmed automatically.
Traffic begins flowing according to the new desired configuration.
This process occurs continuously and transparently, allowing operators to manage networking through OpenStack APIs while OVN handles the underlying implementation.
East-West vs. North-South Traffic in OVN
Before we dive into logical flows and packet tracing, it helps to understand two traffic patterns that OVN handles very differently.
East-West traffic refers to communication between workloads inside the same data center or cloud environment. In OpenStack terms, this means:
VM-to-VM within the same tenant network
VM-to-VM across different tenant networks (routed via a virtual router)
Traffic between VMs and container workloads
East-West traffic typically stays inside the OVN overlay network. It is encapsulated in tunnels (Geneve/VXLAN) and never touches the physical gateway unless routed over L3 provider networks. This communication pattern can be commonly observed in modern software architectures, where backend operations, database replication, and internal API calls are done in private, isolated tenant networks.
North-South traffic refers to communication between workloads and the outside world. Examples include:
A user accessing a web server running on an OpenStack instance via a floating IP
An instance downloading packages from the Internet
User connecting to the cloud environment via a VPN
North-South traffic must exit the OVN overlay and reach the physical network. In OpenStack Neutron, this typically happens through:
Virtual routers with gateway ports attached to a provider network
Floating IPs – which use NAT (DNAT) to map a public IP to a private instance IP
Load balancers or virtual gateways (e.g., OVN’s own distributed gateway ports)
OVN Trace Tool – Debugging Traffic End-to-End
Now that we understand the conceptual path of a packet traveling from a VM to its destination — whether that destination is on the same logical switch, a different tenant network, or the internet. ovn-trace is the tool that lets you verify this path in practice.
Rather than sending real packets and observing what happens, ovn-trace simulates the packet’s journey through OVN’s logical pipelines. It shows you, step by step, which logical flows match, what actions are taken, and where the packet would exit or be dropped.
Some administrators avoid ovn-trace because the output appears complex at first. However, once you understand the pipeline stages, it becomes as readable as tcpdump or tracepath — and far more revealing, because it shows OVN’s internal decision-making, not just network-level behavior.
When the Pipeline Behavior Changes
When you run ovn-trace, the packet’s path through the pipeline depends entirely on its destination. OVN applies different logical pipeline stages based on where the traffic is headed:
Destination inside the same logical switch (same Neutron network) The packet undergoes L2 switching only. The pipeline applies security group ACLs (ingress and egress), performs MAC learning and lookup, and forwards the packet directly to the destination port. No routing or NAT occurs.
Destination in a different logical switch but within the same tenant (requires a logical router) The packet passes through the logical switch ingress pipeline, then enters the logical router pipeline. Here, OVN performs:
TTL decrement
Route lookup
MAC address rewriting
Egress pipeline on the destination logical switch
No NAT is applied unless the destination is on a different tenant network that requires floating IPs.
Destination outside the cloud entirely (external internet or provider network) The packet goes through:
Logical switch ingress
Logical router pipeline (route lookup)
SNAT/DNAT (if the source VM has a Floating IP or the router has SNAT enabled)
Gateway chassis selection (or local routing when DVR is enabled)
localnet port pipeline to egress to the physical network via br-ex
This distinction is critical because a misconfiguration that breaks external connectivity (e.g., missing SNAT) won’t affect internal east-west traffic. ovn-trace makes this clear by showing you exactly which pipeline stages are traversed and where the packet stops.
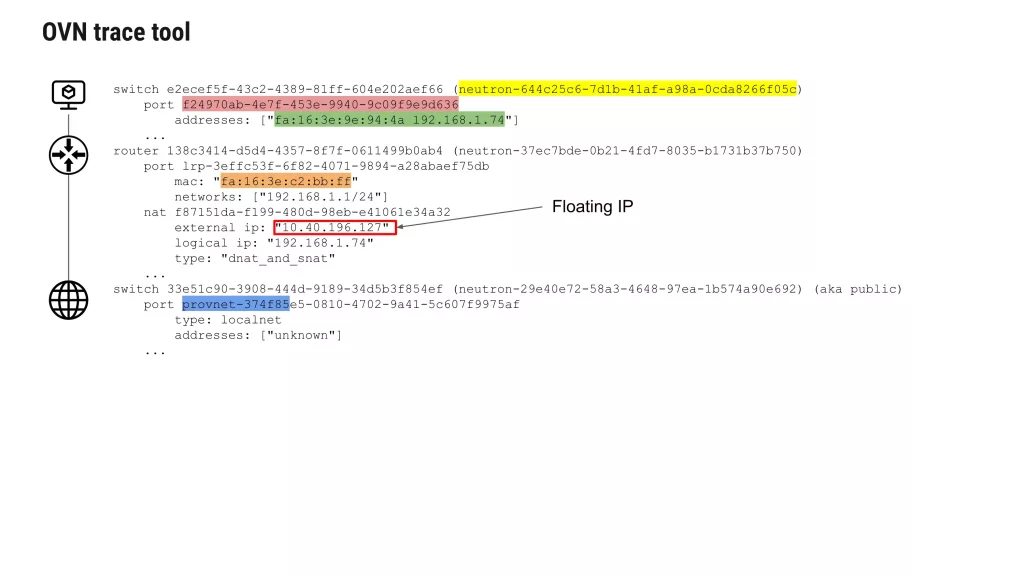
Example Trace: Unicast TCP Traffic to the Internet
In the example below, we trace traffic originating from a VM on the private network:
Packet is forwarded to the localnet port on the provider network.
Egress ACLs are evaluated.
Packet exits via the provnet-374f85… port, which maps to physical bridge br-ex.
The trace output shows exactly this progression, confirming that NAT and routing are working as expected.
Adjusting Verbosity
You can control how much detail the trace shows:
ovn-trace --summary ... # High-level stages only ovn-trace --minimal ... # Minimal output (just the result) ovn-trace --detailed ... # Full pipeline with all matches and actions
When to Use ovn-trace
Use ovn-trace when:
A VM cannot reach a specific destination, but other VMs on the same network can.
You suspect a NAT or routing misconfiguration.
You want to confirm which gateway chassis is handling a particular flow.
Security group ACLs appear to be dropping traffic.
You need to verify that a change (e.g., adding a Floating IP) has been applied correctly in the OVN pipeline.
What ovn-trace Cannot Do
It does not send real packets, so it cannot detect physical network issues (e.g., cable failures, switch misconfiguration).
It does not test actual performance or latency.
It relies on the current state of the OVN databases — if the databases are out of sync, the trace reflects that incorrect state.
Despite these limitations, ovn-trace is one of the most valuable debugging tools in the OVN ecosystem. Once you become comfortable with its output, troubleshooting becomes a matter of reading the pipeline rather than guessing at the problem.
Understanding Neutron to OVN Mapping
Before diving into specific resource mappings, it is helpful to understand a fundamental principle: almost every Neutron object has a direct counterpart in OVN. This one-to-one correspondence is what makes OVN debugging systematic rather than opaque.
When you create a network, subnet, port, router, or security group in OpenStack, the ML2/OVN mechanism driver translates that API request into entries in the OVN Northbound Database. The ovn-northd daemon then converts those logical entries into flow instructions in the Southbound Database, which are finally pushed to ovn-controller on each compute and gateway node.
The following sections show the exact mapping for each Neutron resource type — including the specific ovn-nbctl and ovn-sbctl commands you can use to verify that Neutron’s configuration has propagated correctly into OVN.
Logical Flows vs. Physical Flows
One of the most valuable concepts in OVN is the separation between logical flows and physical flows.
Logical flows operate at the level of your virtual network topology. They reference objects like logical switches, logical routers, and logical ports. A logical flow might say: “Packets from logical port A to logical port B on the same logical switch are allowed.” You don’t need to deal with physical interfaces, tunnel IPs, or MAC addresses here.
Physical flows (OpenFlow rules) exist inside OVS on each hypervisor. They reference physical ports like eth0, tap devices, tunnel interfaces, and exact match fields like VLAN tags or tunnel keys. These flows are generated automatically by ovn-controller based on the logical flows.
Why does this matter? When troubleshooting, you might run ovn-sbctl lflow-list, which shows you logical flows – the intent. When you run ovs-ofctl dump-flows br-int, you are looking at physical flows – the actual forwarding rules installed in the kernel. A mismatch between the two is often the root cause of connectivity issues.
Key OVN CLI Tools for Troubleshooting
Before we move on to the troubleshooting guide, here are some essential OVN commands you will use:
Command
Purpose
ovn-sbctl show
Display chassis and port bindings
ovn-sbctl lflow-list
List all logical flows in the SB DB
ovn-sbctl dump-flows
Show OpenFlow flows generated by OVN (alternative view)
As already outlined, OVN introduces several abstractions that simplify network management. Let’s have a closer look at those.
Logical Switches
Logical switches provide Layer 2 connectivity between workloads.
Unlike physical switches, they exist entirely in software and can span multiple hosts.
A logical switch can connect virtual machines regardless of where they are physically located in the data center.
Logical Routers
Logical routers provide Layer 3 connectivity between logical networks.
These routers support:
Static routing
Distributed routing
NAT
External connectivity
Unlike traditional centralized routers, OVN routers can distribute routing functionality throughout the environment for high availability.
Logical Ports
Logical ports represent attachment points between workloads and logical networks. Every virtual machine interface is typically associated with a logical port.
OVN uses these ports to determine where traffic should enter and exit the logical topology.
Access Control Lists (ACLs)
ACLs define security policies governing traffic between workloads. Examples include:
Allowing SSH access
Allowing access only to certain ports (e.g. 443)
Enforcing tenant isolation
OVN translates these logical policies into dataplane enforcement rules automatically.
Network Address Translation (NAT)
OVN supports multiple forms of NAT including:
Source NAT (SNAT)
Destination NAT (DNAT)
Floating IP mappings
NAT policies are associated with logical routers and distributed throughout the environment.
Following a Packet Through OVN
One of the best ways to understand OVN is to trace a packet’s journey from a virtual machine to its destination — whether that destination is another VM on the same compute node, a VM on a different node, or an external server on the internet.
This section walks through each logical stage of the packet’s path. Later, we will show how to verify this behavior using the ovn-trace debugging tool.
Stage 1: Packet Leaves the Source VM
A VM sends a packet from its virtual network interface. The hypervisor passes this packet to the OVS bridge br-int (the integration bridge) on the compute node where the VM resides.
The VM has no knowledge of OVN — it simply sees a standard Ethernet interface with a MAC address, IP address, and default gateway. In our example:
VM MAC: fa:16:3e:9e:94:4a
VM IP: 192.168.1.74
Default gateway: 192.168.1.1 (the logical router interface)
Stage 2: Packet Enters the Logical Switch
The ovn-controller on the compute node has already programmed OpenFlow rules into br-int based on the OVN Southbound database. These rules direct packets to the correct logical switch.
Each Neutron network corresponds to an OVN logical switch. When the packet arrives, OVN identifies which logical switch port it came from by matching the inbound interface.
To see the logical switch and its ports:
ovn-nbctl show neutron-<NETWORK_UUID>
For a VM port, the output shows an empty type (“”), confirming it is a regular compute port:
port f24970ab-4e7f-453e-9940-9c09f9e9d636 addresses: ["fa:16:3e:9e:94:4a 192.168.1.74"] type: ""
Stage 3: Layer 2 Resolution (ARP/ND)
If the packet’s destination is on the same logical switch (same Neutron network), OVN performs layer 2 forwarding:
The packet’s destination MAC is looked up in OVN’s logical switch MAC binding table.
OVN determines which logical switch port has that MAC address.
If the destination is on a different compute node, OVN encapsulates the packet in a tunnel (VXLAN or Geneve) and forwards it to the correct hypervisor.
If the destination MAC is unknown (e.g., the VM is trying to reach a new IP), the VM first sends an ARP request (for IPv4) or an ND (for IPv6). OVN handles ARP natively without flooding the entire network — it responds locally if the IP belongs to a known port.
Stage 4: Packet Reaches the Logical Router (East-West Traffic)
When a VM sends a packet to an IP address on a different Neutron network that is connected via a shared logical router, the packet must pass through the logical router.
The VM sends the packet to its default gateway MAC address. OVN recognizes that this MAC belongs to a logical router port attached to the logical switch.
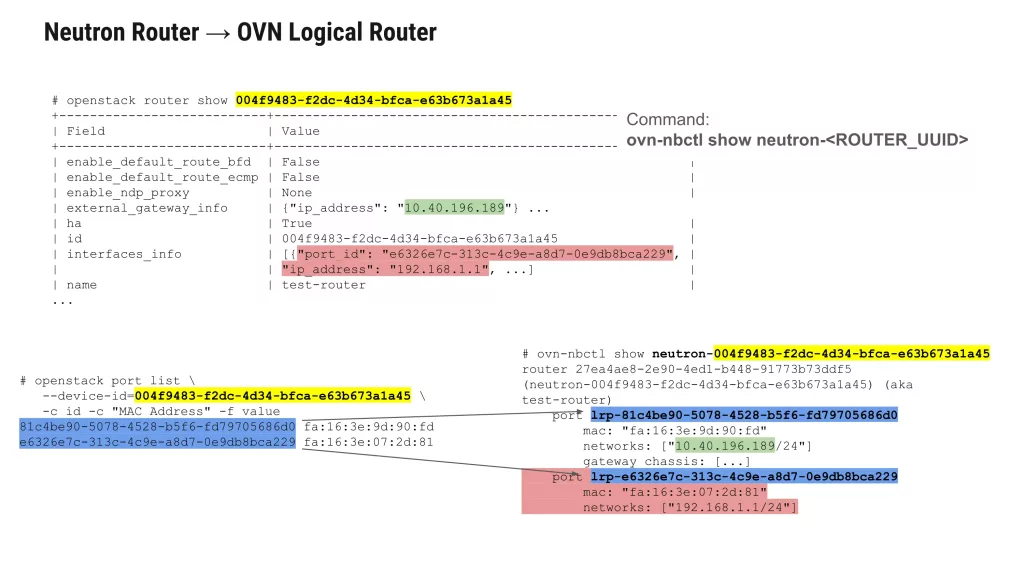
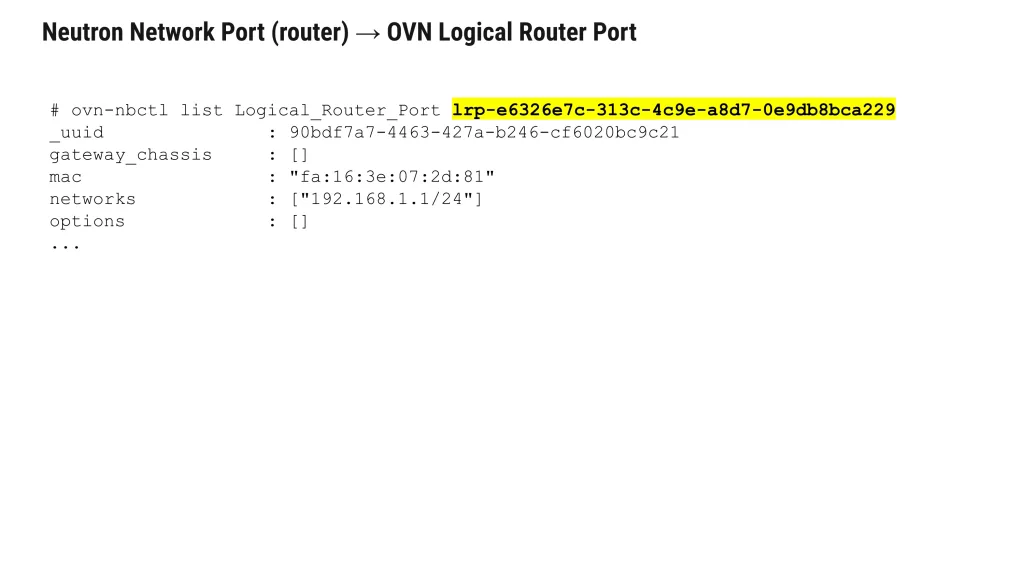
Inspect the logical router and its ports:
ovn-nbctl show neutron-<ROUTER_UUID>
Example output shows both internal and external ports:
router 81c4be90-5078-4528-b5f6-fd79705686d0 (test-router) port lrp-71a2b3c4-d5e6-4789-a0b1-c2d3e4f56789 mac: "fa:16:3e:c2:bb:ff" networks: ["192.168.1.1/24"] port lrp-81c4be90-5078-4528-b5f6-fd79705686d0 mac: "fa:16:3e:73:78:ee" networks: ["10.40.196.189/24"]
The internal router port (lrp-71a2b3c4…) is connected to the tenant network. Where an external router port (lrp-81c4be90…) connects to the provider network.
When the packet enters the logical router:
OVN decrements the TTL.
OVN looks up the destination IP in the router’s routing table.
OVN rewrites the source MAC to the router’s egress port MAC and the destination MAC to the next hop’s MAC.
The packet is forwarded to the logical switch attached to the destination network (for east-west traffic) or to the gateway chassis (for north-south traffic).
Stage 5: North-South Traffic and NAT
If the packet’s destination is outside the OpenStack cluster (e.g., 8.8.8.8), the logical router forwards it to a gateway chassis that has external connectivity.
For a VM with a Floating IP, OVN applies NAT rules. To view the NAT configuration you can run:
SNAT (Source NAT) — Rewrites the source IP from the VM’s fixed IP to the Floating IP (or gateway external IP) so return traffic can be routed back.
DNAT (Destination NAT) — Rewrites the destination IP of incoming traffic from the Floating IP to the VM’s fixed IP.
In distributed mode (DVR enabled), the NAT happens on the compute node where the VM resides. In centralized mode, it happens on the dedicated gateway node.
To identify the active gateway chassis you need to run:
ovn-nbctl lrp-get-gateway-chassis <PORT_UUID>
ovn-sbctl get Chassis < CHASSIS_ UUID> host name
Stage 6: Egress to Physical Network
Once the packet has passed through the logical router and any NAT rules, it must leave the OVN overlay and enter the physical network.
This happens via a localnet port on the provider network’s logical switch. The localnet port is mapped to a physical bridge (typically br-ex) on the gateway chassis using bridge mappings.
Inspect the chassis bridge mappings:
ovn-sbctl get Chassis <CHASSIS_UUID> external_ids
Expected output:
{ovn-bridge-mappings="public:br-ex", ...}
Where public is the name of the provider network. The ovn-controller on the gateway chassis strips the OVN tunnel encapsulation (if any) and forwards the raw Ethernet frame onto br-ex, which then sends it out the physical NIC to the external network.
Stage 7: Return Path and Stateful Tracking
OVN maintains connection tracking (conntrack) for stateful services like NAT and security groups. When a response packet returns from the provider network:
It enters via br-ex on the gateway chassis.
OVN reverses the SNAT/DNAT translation using the connection tracking state.
The packet is encapsulated and tunneled to the appropriate compute node.
The compute node’s ovn-controller delivers the packet to the original VM.
For security groups, OVN uses ACLs attached to Port Groups. Each ACL rule is evaluated in the pipeline before forwarding decisions are made.
Verifying the Packet Path with ovn-trace
The conceptual path described above can be simulated using OVN’s built-in trace tool. For example, tracing TCP traffic from our VM to 8.8.8.8:
The output will show each pipeline stage: ingress from the logical switch, routing decision, NAT application, and egress to the provider network.
Summary of the Packet’s Journey
Step
Location
Action
1
Source VM
Packet leaves VM’s virtual interface
2
br-int on compute
Packet enters OVN logical switch
3
Logical switch
Layer 2 forwarding or ARP resolution
4
Logical router
Routing, TTL decrement, MAC rewrite
5
Gateway chassis (or local compute with DVR)
SNAT/DNAT for Floating IPs
6
br-ex on gateway
Encapsulation stripped, egress to physical network
7
Return path
Connection tracking reverses NAT, tunnel back to compute
Understanding this flow makes it much easier to diagnose where a packet might be dropped — whether at the logical switch level (port binding issues), the router level (missing routes or incorrect NAT), or the physical egress level (bridge mapping problems).
Final Thoughts
This guide has walked through OVN’s architecture, the Neutron-to-OVN mapping, packet flow mechanics, and practical troubleshooting scenarios. By now, the underlying pattern should be second nature:
Neutron API calls → OVN Northbound DB (logical intent and configuration) ovn-northd → OVN Southbound DB (physical realization and binding) ovn-controller on each hypervisor → OpenFlow rules in OVS (actual data plane enforcement)
This three-tier transformation is the heart of OVN’s power — and, occasionally, its complexity. When an OpenStack network isn’t working as expected, resist the urge to jump straight to packet captures. Instead, adopt a disciplined, top-down approach: start at the Southbound DB to see what OVN believes should be happening on the wire. Then verify the Northbound DB to confirm what Neutron originally requested. Compare the two. In most cases, the root cause lives in the gap between intent and realization — a duplicate chassis, stale binding, an unprocessed logical flow, or a misapplied ACL.
Beyond the core flow, remember to check the Chassis table for node liveness, the Binding table for port ownership, and the Logical_Flow table for pipeline ordering. Tools like ovn-trace are invaluable for simulating packet paths without touching production traffic, while the DB sync tool can help you reconcile state when the control plane and data plane fall out of alignment.
Let the commands and workflows featured here — from ovn-nbctl find to ovn-sbctl lflow-list to the trace utility, become trusted companions in your OVN debugging.
To learn more about OVN, OpenStack and other technologies visit Cloudification Blog.
Following the tradition of our previous Project Teams Gathering (PTG) summaries, the April 2026 PTG brought together over 35 teams and hundreds of contributors, operators, and open-source enthusiasts for a week of virtual collaboration. On the OpenStack side, the community was coming off the launch of the 2026.1 “Gazpacho” release of OpenStack and spent the week diving straight into the 2026.2 “Hibiscus” cycle.
Planting the Seeds for “Hibiscus”
With the Hibiscus cycle now underway, the OpenStack service teams were buzzing post “Gazpacho” release! You can find OpenStack team summaries below.
Every PTG reminds me why this community works: the Four Opens. Whether we were debating technical specs, or troubleshooting niche use cases, the focus is on open collaboration and our global community working together to make open software.
If you couldn’t make it a session, I highly recommend checking out the team etherpads. These etherpads are full of the details that made this PTG a success.
Today, the OpenStack community is proud to announce the release of OpenStack 2026.1 Gazpacho, the 33rd release of the world’s most widely deployed open source cloud infrastructure software. But beyond the features and improvements, Gazpacho tells a deeper story: one of a global community continuing to come together to solve real infrastructure challenges through open collaboration.
Every OpenStack release is the result of thousands of contributions, countless hours of collaboration, and a shared commitment to building open infrastructure that works in production. Gazpacho is no exception.
A Community Driving Momentum
The Gazpacho cycle reflects growing momentum across the OpenStack ecosystem. Over the past six months, around 500 contributors from 100 organizations worked together to deliver more than 9,000 code changes across OpenStack services, an increase in activity compared to the recent OpenStack 2025.1 Flamingo release.
Behind those numbers are developers, operators, users, and organizations from across the globe collaborating in the open to build software that powers private clouds, edge environments, and increasingly, AI infrastructure.
The scale of collaboration doesn’t stop at code. OpenDev’s Zuul CI system continues to run more than one million jobs per release cycle, ensuring that every contribution is tested, validated, and production-ready before it reaches users.
This level of rigor and transparency is what makes OpenStack unique. It’s not just about shipping features, it’s about building trust.
Open Collaboration, Global Impact
One of the most powerful aspects of the OpenStack community is its global nature. Contributors span hundreds of organizations and nearly every region of the world, bringing diverse perspectives and real-world requirements into the project.
In the Gazpacho release, 40% of contributions came from European contributors highlighting how regional priorities like digital sovereignty are shaping the future of open infrastructure.
This is the strength of open source: the ability to reflect the needs of different industries, geographies, and use cases, all within a shared codebase. Whether it’s telecom operators optimizing for performance, enterprises migrating off proprietary platforms, or governments building sovereign cloud infrastructure, those needs show up directly in the software.
Solving Operator Challenges Together
At its core, OpenStack has always been driven by operators and Gazpacho continues that tradition.
This release focuses heavily on simplifying operations, improving workload mobility, and enabling infrastructure to run consistently across increasingly complex environments. These priorities don’t emerge in isolation; they come directly from community feedback, real-world deployments, and ongoing collaboration between users and contributors.
For example, enhancements in Ironic introduce more intelligent automation, reducing the need for manual configuration and making it easier to manage bare metal infrastructure at scale. Features like autodetect deployment interfaces and automatic protocol detection reflect a broader goal: letting operators focus less on configuration and more on outcomes.
Similarly, improvements in workload migration, such as enhanced cross-zone strategies and live migration support for sensitive workloads, address one of the most urgent challenges facing infrastructure teams today. As organizations accelerate migration from proprietary platforms, seamless mobility across environments is no longer optional; it’s essential.
Performance and Flexibility for Modern Workloads
The Gazpacho release also brings significant improvements in performance and responsiveness, shaped by the needs of operators running at scale.
Enhancements like parallel live migrations, asynchronous APIs, and better I/O handling in Nova are direct responses to real-world demands for faster, more efficient infrastructure. At the same time, expanded hardware support, from GPUs to FPGAs and beyond, ensures OpenStack can support the growing diversity of modern workloads, including AI and data-intensive applications.
These improvements are not built in isolation. They are the result of collaboration across projects—Nova, Neutron, Ironic, Manila, Cyborg—and across contributors who understand that infrastructure is a system, not a set of silos.
A Platform That Evolves with Its Community
Thirty-three releases in, OpenStack continues to evolve, not by chasing trends, but by responding to the needs of the operators running the software in production. As of October 2025, the global OpenStack footprint exceeds 55 million compute cores.
The introduction of the SLURP (Skip Level Upgrade Release Process) model is a perfect example. Designed with operators in mind, SLURP allows for annual upgrades instead of every six months, reducing operational burden while maintaining a predictable release cadence.
It’s a reminder that innovation in OpenStack isn’t just about features; it’s also about how the software is delivered, maintained, and operated over time.
Looking Ahead
Gazpacho represents more than a release. It’s a snapshot of a community in motion, growing, adapting, and continuing to build infrastructure that meets the needs of today while preparing for what comes next.
From enabling workload migration at scale to supporting AI-driven infrastructure and advancing digital sovereignty, the direction of OpenStack is clear: open collaboration remains the foundation.
And that foundation is only as strong as the people behind it.
To everyone who contributed to the Gazpacho release—code, documentation, testing, feedback, and beyond—thank you. This is your release.
Mark your calendars for October 17–19, 2025, when the OpenInfra community converges on École Polytechnique in Paris‑Saclay for the much‑anticipated OpenInfra Summit Europe. The schedule was just published today, and among the open infrastructure focused tracks, OpenStack remains central—featuring in core presentations, Forum discussions, workshops, and keynotes.
The OpenInfra Summit schedule is curated by experts from the global community who volunteer their time to make the content as engaging and representative as possible. Some highlights among the 80+ OpenStack sessions include:
Keynote attendees will see a multi-participant, simultaneous demo highlighting the variety of paths organizations can take to migrate workloads from VMware to OpenStack. Participants currently include Canonical, Rackspace and ZConverter.
Attending OpenStack sessions at OpenInfra Summit Europe offers a chance to:
Gain early access to Flamingo roadmap discussions
Learn from migration success stories and production use-cases
Network with contributors, team leads, and users worldwide
Influence the future direction of OpenStack through Forum collaboration (The Forum CFP is open until 8 July!)
If you’re passionate about hybrid clouds, open infrastructure, and cutting-edge OpenStack innovation, these sessions are unmissable. Check out the full agenda—and don’t miss your chance to engage, learn, and contribute at the OpenInfra Summit Europe this October!
In the wake of Broadcom’s 2023 acquisition of VMware, the enterprise IT world found itself at a crossroads. Rapid, unexpected changes to VMware’s licensing model sent shockwaves through thousands of organizations, forcing a stark choice: stay and absorb dramatic cost increases—or seek out an alternative platform capable of handling mission-critical workloads.
Enter OpenStack
For many organizations, OpenStack was that cloud they looked into 10 years ago and decided that it wasn’t the right platform for them at the time. Since then, thanks to thousands of contributors and hundreds of organizations, OpenStack has matured significantly into a stable platform trusted to handle any workload. It has simplified and addressed feedback from users. It has been adopted and evolved by thousands of developers at hundreds of organizations all around the globe. OpenStack has evolved to support complex, large-scale infrastructure with power and flexibility.
With a second look, organizations around the world are discovering just how much the OpenStack marketplace has grown in the last decade. There have been 21 releases since 2015 and with each one there have been numerous upgrades and advancements. These organizations have a lot of questions though; namely, how does a migration from VMware to OpenStack work?
Available Today: A Comprehensive VMware-to-OpenStack Migration Guide
Last year, the OpenInfra Member community collaborated to create the VMware Migration Whitepaper to start a public dialogue positioning OpenStack as an option in this quest for a virtualization alternative. It helped educate this market on the why of the situation – why OpenStack could be a strategic, cost saving alternative. As a result, questions are now focused on the how.
Today, I am proud to introduce the VMware Migration Guide, which answers these questions. The idea behind the guide is to build on the foundation that last year’s white paper began. The Guide’s aim is to prime the organizations for making the move to OpenStack by helping with the planning stages, the candid assessment of the existing stack, and setting up a mindset for modernizing infrastructure and the operating model.
The Guide was created by a group of OpenInfra community members with experience and knowledge in this space and includes:
Case Studies of real world workload migration
Reference architectures to show how an OpenStack cloud offering might be laid out and how that can serve the workload that is currently on VMware
Considerations, comparisons and the clear benefits of moving to OpenStack to avoid vendor lock-in and capitalize on all that comes with leveraging an open source solution
How OpenStack Introduces Benefits of Open Source to a Previously Locked In Crowd
As organizations consider the move from a proprietary solution like VMware to an open source based product, the benefits are not limited to a reduction in licensing costs. The most impactful benefit is actually the dissolution of vendor lock-in; you are no longer bound to the decisions or product roadmap of a single vendor. The OpenStack Marketplace proves there is an entire ecosystem for you to explore and interoperability you can leverage until you find the right partner.
Beyond the Marketplace, OpenStack is backed by a global community openly developing code that is better tested and more robust. Now is the time for your organization to take another look at OpenStack. Learn more about the benefits and challenges of VMware to OpenStack Migration and join this global movement.
Oria Weng is a third-year honors student studying computer science at Oregon State University, working at the Oregon State University Open Source Lab (OSUOSL).
What Open Infrastructure project are you working with, and what made you interested in that project, as opposed to some of the other options? What was the hardest part about getting started?
I believe it was Kendall Nelson who connected the OSUOSL with the internship program; I joined work on OpenStack Client (python-openstackclient), the command line client, after Antonia Gaete, another past intern, had started working on it. It made sense logistically for us to work under the same mentors (Stephen Finucane and Artem Goncharov) and on the same project, but I did like specifically working on identity because things like users, projects, etc. were things I had to use pretty often in my own usage of OpenStack. Plus, it was a good opportunity to learn more about security concepts like authorization and authentication. Later, Artem introduced us to his API schema work on Keystone, the identity service, and invited us to help with that. I’ve really enjoyed working with APIs in the past, so this sounded like a fun opportunity. I especially liked the idea that enforcing a strict API schema could (potentially) make it easier to find inconsistencies and bugs, as well as improve the understandability and documentation of Keystone.
What was the hardest part about getting started?
This was my first time working on a big open-source project at this scale, so the hardest part for me was understanding how the codebase fit together and figuring out which of the moving parts I should change to accomplish something. What helped me the most was to look at examples of other changes – for example, I studied Antonia’s changes as I was starting out, since she had started at OpenStack earlier than me and was doing similar work. It also helped a lot to have mentors who knew the codebase inside and out and were willing to answer any questions that came up.
What could have made the getting-started process easier?
I think the docs were pretty overwhelming for me as I was starting out – each project has different categories of references and guides as well as multiple project versions; there are also both contributor guides for individual projects and ones for OpenStack overall. Fortunately, I had help from mentors like Kendall, Stephen, and Artem to figure things out, but I think a short guide for total beginners on how to navigate the projects and their docs would be helpful. 🙂
How have you contributed to the community?
For OpenStack, I’ve primarily been helping to migrate OpenStack Client commands to use the OpenStack SDK (to move away from keystoneclient) as well as adding API schema validators to Keystone. In terms of the open source community in general, this is my third year working at the OSUOSL, where we provide hosting and other services to over 160 open source projects. I think that’s pretty cool!
What’s the biggest benefit from your involvement? (hard or soft skills, connections, etc)
One of the biggest benefits for me was just getting used to development on a big open source project. Before going in, I didn’t really have a good idea of how open source development really worked; I learned a lot about best practices and how to communicate.
What advice do you have for students who want to get started with open source?
Don’t be afraid to ask questions! As I was starting out, I probably looked even sillier pretending I knew what was going on when I didn’t, than I would have if I’d just asked an “obvious” question.
As the academic year wraps up, seniors at Dickinson College have completed their capstone course, where they learned a lot during the past year, including new concepts, how OpenInfra works, working with the Swift core team, and we getting to attend the Project Teams Gathering (PTG).
This year, James Nguyễn, Nathan Nguyễn, and Boosung Kim were among the fortunate few who had the chance to work with OpenStack. In a recent interview with one of the students, Boosung Kim shared insights into how he became acquainted with OpenStack, what surprised him the most, the challenges he encountered, and the advice he’d offer to future students.
Boosung is a senior double majoring in Computer Science and Math, graduating this year. He is currently wrapping up his final semester while contributing to OpenStack Swift. Outside of school, he enjoys attending hackathons and swimming!
What Open Infrastructure project are you working with and what made you interested in that project, as opposed to some of the other options?
I’m working with OpenStack Swift. I was drawn to it because of my interest in large-scale systems and backend infrastructure. Swift stood out from other projects due to its clean design, active community, and relevance to the kind of distributed systems I want to build professionally.
How did you get started? What was the hardest part?
I got started by joining Dickinson College’s seminar focused on open source development, where I chose Swift for a technical deep dive. I began by exploring the codebase, setting up a dev environment, and meeting the Swift team during the 2024 PTG.
The hardest part was grasping new concepts like race conditions, erasure coding, and heartbeats. These were outside the scope of my usual coursework, so it took extra time to understand how they fit into a distributed system like Swift.
What could have made the getting started process easier?
Clearer beginner-focused documentation on core concepts like consistency, replication, and concurrency in Swift would have helped. But the dev team was willing to hop on a call to explain these concepts in-depth, so everything worked out regardless.
How have you contributed to the community?
I’ve contributed code patches to the Swift project, participated in review discussions, and gave a tech talk at my college to introduce others to OpenStack and Swift. I hope that my contributions can be of help to Swift users and that more students from my college will work with OpenStack.
What’s the biggest benefit from your involvement?
The biggest benefit has been learning how real-world distributed systems are built and maintained. I also gained experience navigating large codebases, writing production-level code, and communicating effectively in an open-source community.
What advice do you have for students who want to get started with open source?
Don’t try to perfect your patches before submitting for review like I did. Aim for quick, purposeful iterations so that you can get reviews fast and ship fast.
The OpenInfra Project Team Gathering took place April 7 to 11, earlier this month. A variety of OpenStack teams, covering the basic OpenStack services, pop up working groups, among other more horizontal view teams met to have technical discussions throughout the week. Discussions ranged from ongoing feature work, to reviewing feedback on the most recent Epoxy release, to planning for the future and everything in between.
Some highlights were the revival of interest in Watcher which has been rejuvenated by a number of organizations looking to migrate from VMware and OpenStack being well poised as an alternative. The technical committee held a community leaders forum to bubble up issues affecting teams and reignite awareness about the Vulnerability Management Team and ongoing community goals. Also this PTG, OpenStack Operators and community members gathered to discuss how to better engage with people in operations roles and re-frame the way they collaborate as a group and participate in the larger community.
For more information about discussions that went on at the PTG, you can find find a list of the team summaries that have been published below.
Thank you to everyone that participated in this PTG! If there are any summaries missing from this list, please reach out to [email protected] to get them added here.
The OpenStack community’s latest release, 2025.1 Epoxy, marks an important milestone in the project’s evolution. With the release of OpenStack Epoxy, the project continues to improve its capabilities, positioning itself as a more viable alternative to proprietary solutions like VMware. Packed with a range of new features, security enhancements, and hardware enablement improvements, Epoxy is poised to support more complex and demanding workloads while offering more efficient management tools for cloud administrators.
OpenStack’s adoption is on the rise, and this release demonstrates the community’s commitment to its growth and evolution in the face of industry trends and opportunities. The 31st release of OpenStack is the result of contributions from around 450 developers from leading organizations such as BBC R&D, Blizzard Entertainment, Canonical, Ericsson, Mirantis, NVIDIA, and others. Together, they’ve delivered more than 7,600 changes, including new features and significant maintenance updates. This release also comes as the OpenStack community celebrates its 15th anniversary, a testament to its continued relevance and importance in the cloud computing world.
Strengthening OpenStack’s Position as a VMware Alternative
Broadcom’s acquisition of VMware and subsequent licensing changes have incentivized organizations around the world to re-evaluate their virtualization strategy. OpenStack has emerged as a leading VMware alternative, and the upstream community is evolving OpenStack to address this market opportunity. One of the standout features of OpenStack Epoxy is the enhanced VMware migration capabilities, especially through the integration of Prometheus within the Watcher project. Watcher is a component of OpenStack designed to optimize resource allocation. With the addition of a Prometheus data source, OpenStack can now more effectively monitor existing VMware infrastructures, making it easier to track performance and detect bottlenecks during migration. This feature is invaluable for businesses looking to migrate from VMware to OpenStack, as it ensures a smooth transition without performance degradation.
Additionally, Epoxy introduces improved support for a range of storage solutions through the Cinder project. Cinder, OpenStack’s block storage service, now includes updates for many supported hardware drivers, such as NetApp, Pure Storage, and Hitachi. These improvements help organizations that rely on specific storage solutions to migrate their workloads to OpenStack more easily. After migration, the compatibility between OpenStack and existing storage infrastructures ensures seamless data access, reducing the risks associated with switching to a new platform.
Enhancing Security Features
Security remains a top priority in the Epoxy release. A significant upgrade comes to Manila, OpenStack’s shared file system service. In Epoxy, Manila users can now modify the access level of share access rules, switching from “read-only” to “read-write” or vice versa. This gives administrators greater control over who can modify and access shared data, improving the overall security of the cloud environment by reducing the risk of unauthorized changes.
Additionally, Manila users can now set and modify share server characteristics through share network subnet metadata. This feature allows administrators to define permissible modifications through a configuration option called driver_updatable_subnet_metadata. The result is improved network isolation and segmentation, reducing the risk of lateral movement in case of a security breach. By ensuring that different data sets are isolated on separate subnets, the security of the network is significantly enhanced.
Another noteworthy security feature comes to Octavia, OpenStack’s load balancing service. In this release, Octavia now supports custom neutron security groups for load balancer VIP (Virtual IP) ports. By associating specific security groups with VIP ports, administrators can ensure that only approved traffic types are allowed to access the load balancer, further reducing the risk of unauthorized access.
Improving Hardware Enablement
OpenStack Epoxy also brings important hardware enablement updates, particularly in support of AI and machine learning workloads. One of the key improvements is the addition of a new interface in Ironic, OpenStack’s bare-metal provisioning service. This interface allows for the deployment of bootable container images directly to a host without intermediate steps, simplifying the deployment process for operators and users alike.
Another significant update comes in Nova, OpenStack’s compute service, with improvements to PCI passthrough. PCI passthrough allows virtual machines to access physical hardware devices directly, and the Epoxy release expands support for the vfio-PCI variant drivers, including Nvidia GRID on Ubuntu 24.04. This enhancement ensures that OpenStack can more effectively support AI workloads by allowing for the direct use of GPUs and other specialized hardware in virtualized environments. Additionally, this update enables live migration of instances using these PCI devices, further improving the flexibility and scalability of OpenStack environments.
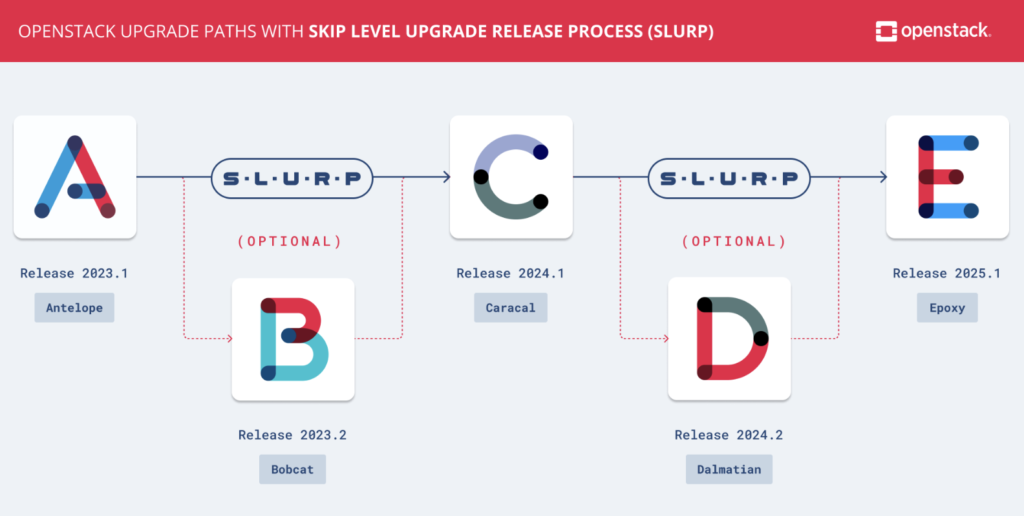
Simplifying OpenStack Upgrades
The OpenStack community continues to focus on simplifying the upgrade process for users. The Skip Level Upgrade Release Process (SLURP), introduced in 2022, allows users to upgrade to the next major release every year rather than every six months. This release cycle simplifies the process for administrators, reducing the frequency of major updates while still delivering new features and security patches. The Epoxy release (2025.1) follows the previous SLURP release (2024.1 Caracal), making it easy for organizations to upgrade directly from one release to the next without worrying about incremental updates.
With enhanced migration tools, improved hardware support, and robust security features, OpenStack continues to evolve to meet the needs of modern cloud environments. The contributions from hundreds of developers and the continued growth of the OpenStack community underscore its importance in the future of cloud computing. Whether you are migrating from VMware or seeking to enhance the security and flexibility of your cloud infrastructure, OpenStack Epoxy is a release worth exploring.