

Storytelling is one of the most powerful means to influence, teach, and inspire the people around us. To celebrate OpenStack’s 10th anniversary, we are spotlighting stories from the individuals in various roles from the community who have helped to make OpenStack and the global Open Infrastructure community successful.
Here, we’re talking to Tim Bell from CERN. He tells the community about how he got started with OpenStack and his favorite memory from the last 10 years of OpenStack.

How did you get started working with OpenStack and what are you doing now?
At the start of the 2010s, CERN was preparing for a significant increase in its computing capacity to meet the needs of the Large Hadron Collider and other experiments. A project was launched to replace our home-written infrastructure tools by community open source solutions, collaborating with other organizations facing similar challenges.
By 2012, we had completed our evaluations and shared the results at the San Diego OpenStack summit and we went into production in July 2013.
In 2020, we’re now running an OpenStack cloud of over 300,000 cores covering more than 90% of the compute resources delivered by the CERN IT department with the CERN storage team providing PBs of ceph block, shares and object space and more than 500 Kubernetes clusters using OpenStack Magnum and 5,000 bare metal servers using OpenStack Ironic.
What is your favorite memory from the last 10 years of OpenStack?
Many OpenStack events and summits have special memories with the close collaboration of the development teams and information exchange with other cloud operators. Among the highlights were the awarding to the CERN team of the first OpenStack superuser award in a unique event in Paris 2014 and the joint CERN and Square Kilometer Array summit presentation in Barcelona 2016.
The OpenStack Scientific Special Interest Group is always a memorable event at each summit with the chance to discuss with other scientific labs around the world on the approaches to using clouds for research.
How did you contribute to the OpenStack community?
One of the principles of the CERN re-engineering of our infrastructure tools was to be able to contribute back changes to the upstream communities. This ensures we can run recent versions of software and also provides a mechanism to share our enhancements with others. The CERN team has made nearly 1000 commits from 34 contributors over the past 8 years. Significant activities have been done in collaboration with industry through the CERN openlab framework such as Keystone Federation (with Rackspace), Magnum containers-as-a-service (Rackspace), Cells v2 (Huawei) and pre-emptible ‘spot’ instances (Huawei).
CERN also contributes to OpenStack governance, where I have been an individually elected member of the OpenStack management board since 2012, was part of the OpenStack user committee for 3 years and other members of the team serve on the user and technical committees along with taking Project Team and Core Lead roles.
We have regularly shared our OpenStack experiences at OpenStack summits and user group events. This includes particularly memorable events where we were able to organize visits to CERN such as the Swiss User Group and the CERN OpenStack day in 2019 which included opportunities for underground visits to the LHC experiments and the anti-matter factory.

What advice do you have for the Stacker community and other growing open source communities based on your experience with OpenStack?
The principle of ‘4 opens’ of the OSF provides the core values of the community. While technologies change frequently and projects must navigate through supporting current users and on-boarding new contributors, OpenStack can evolve within this framework via worldwide collaborations at scale with both the Open Infrastructure project areas and other foundations in the open source world.
If I were to ask you in 2030, what do you think the OpenStack update will be?
By 2030, the High Luminosity Large Hadron Collider (HL-LHC) upgrades would be in place and the computing challenges presented at the CERN OpenStack day will have needed to be addressed such as processing the 1 EB of data expected per year.
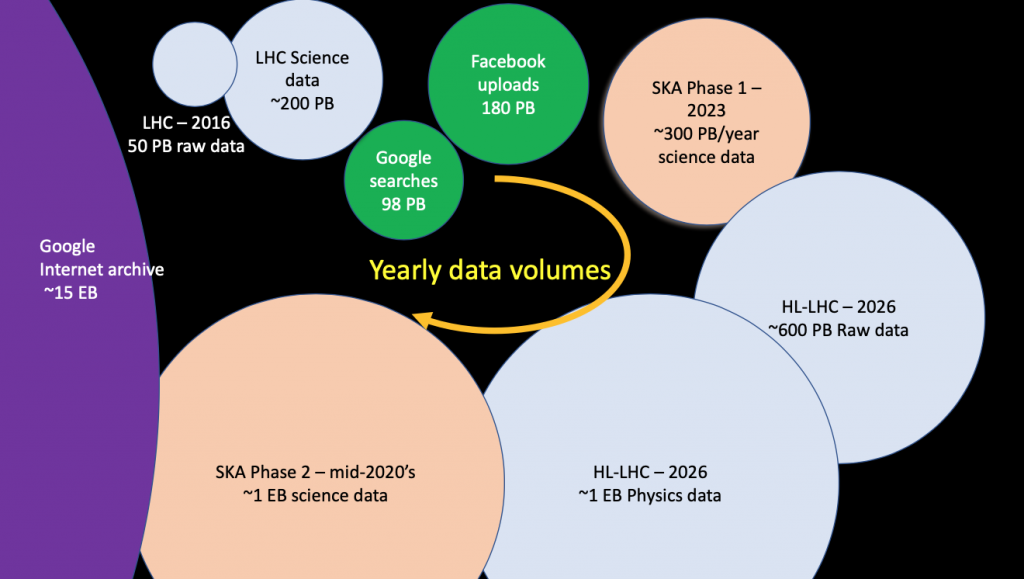
Research is already ongoing with accelerators such as GPUs in the CERN cloud but given the initiative that has recently started at CERN on Quantum Computing, maybe 2030 would be an opportunity for the OpenStack community to add Quantum-Computing-as-a-Service to the project list!
Get Involved
If you’re interested in being featured to tell your stories about OpenStack, please email [email protected].
Follow the #10YearsofOpenStack hashtag on Twitter and Facebook and share your favorite memories of OpenStack with us!
Follow us on
Twitter: twitter.com/OpenStack
Facebook: facebook.com/OpenStack
WeChat ID: OpenStack









Leave a Reply